

Market leadership starts here

More than 23,000 customers trust CrowdStrike to protect what matters most
- Intel
- Target
- Kelly McCracken, SVP of Detection & Response




- Adversary slide 1
- Adversary slide 2
- Adversary slide 3
- Adversary slide 4
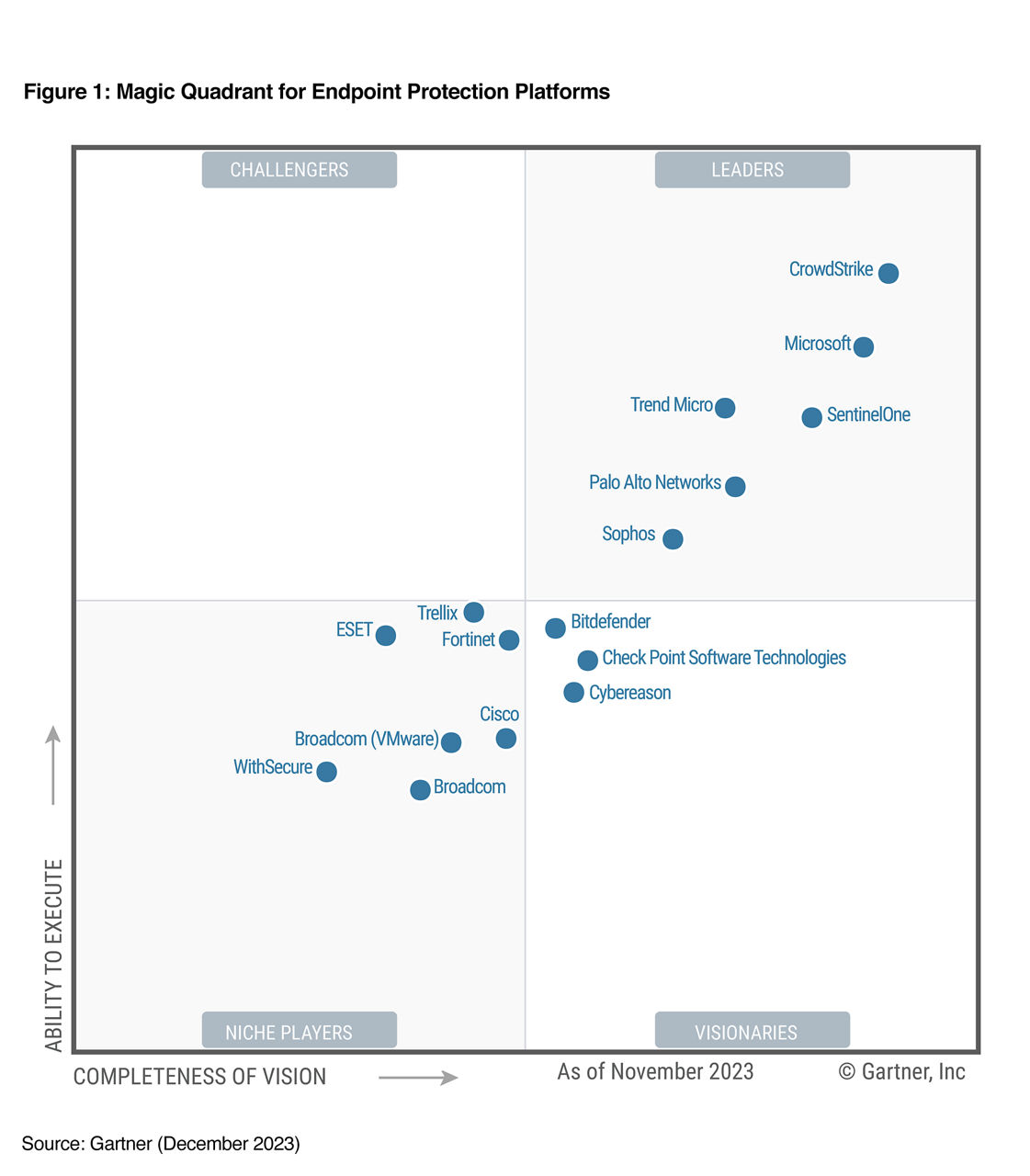
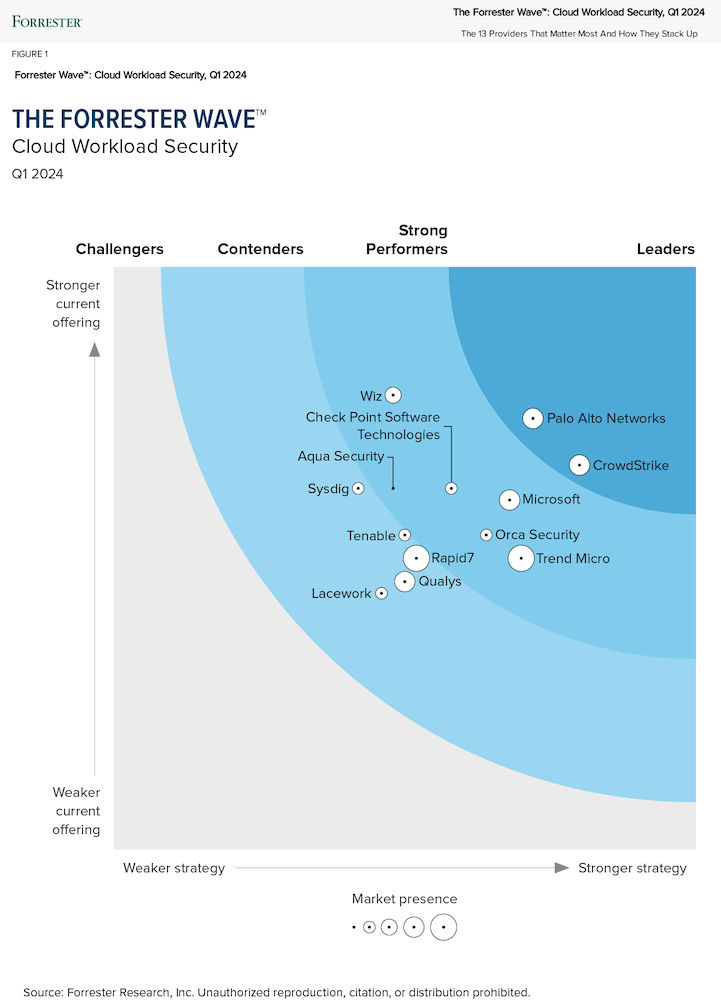
CrowdStrike is continually recognized as a leader by 3rd party organizations and customers. Learn more at crowdstrike.com/leader.
1 Customer expectations are based on calculations made by CrowdStrike with data provided by customers or prospective customers who conduct a Business Value Realized or Business Value Assessment. Average savings are from the Total Economic Impact™ of CrowdStrike Falcon Complete, commissioned by CrowdStrike, February 2021. Results are for a composite organization as stated in the study. Individual results may vary by customer.
2 Gartner, Magic Quadrant for Endpoint Protection Platforms, Peter Firstbrook, Chris Silva, 31 December 2022.
Gartner is a registered trademark and service mark and Magic Quadrant is a registered trademark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved. This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from CrowdStrike. Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner research organization and should not be construed as statements of fact. Gartner disclaims all warranties, express or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.